【ページ更新日:2020年10月4日】
毎日Pythonでは、毎日簡単なPythonのプログラムコードを紹介していきます。
今日は「スクレイピング」の簡単な手順を紹介します。
今日のプログラム
コードは次の通りです。
どのようなプログラムか考えてみてください。
from bs4 import BeautifulSoup
import requests
url="https://weather.yahoo.co.jp/weather/jp/13/4410.html"
r = requests.get(url)
soup=BeautifulSoup(r.text,'html.parser')
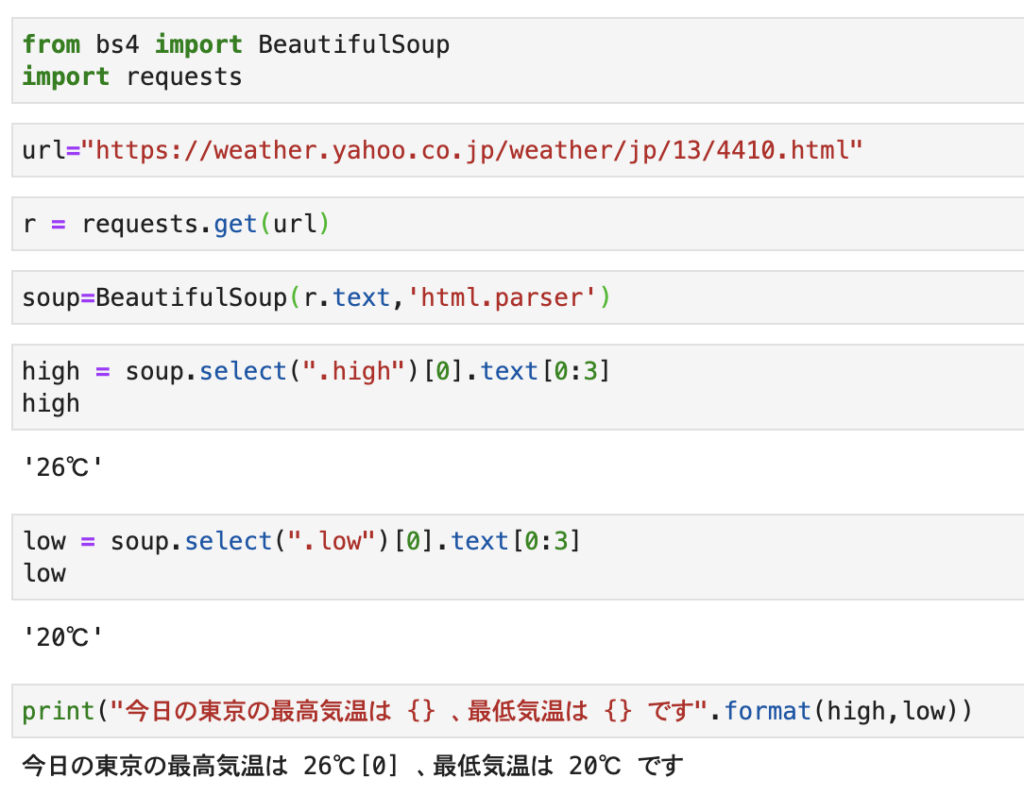
high = soup.select(".high")[0].text[0:3]
low = soup.select(".low")[0].text[0:3]
print("今日の東京の最高気温は {} 、最低気温は {} です".format(high,low))
Pythonはインテンド(行頭のスペース)がズレるだけでエラーの原因になります。
コピペする場合は次のコードからしてください。
コードのURLはコチラです。
今日のポイント
- from
- import
- bs4
- BeautifulSoup
- requests.get(url)
- BeautifulSoup(r.text,'html.parser')
- select(".high")[0].text[0:3]
今日の出力
今日の出力は次の通りです。

今日のコードの説明
まず、今日のポイントについて説明します。
fromとimport
- fromとimportはモジュールをインポートするときに使用します
- モジュールとは、関数やクラスを1つのファイルにまとめたものです
- モジュールをインポートすることで便利な関数やクラスを使うことができるようになります
- インポート方法は次のとおり、コードの最初に書きます
from モジュール名 import 関数/クラス等
bs4
- bs4は、スクレイピングなどのhtmlファイルを処理する関数がセットになったモジュールです
requests.get(url)
- Python の HTTP ライブラリ
requests.get('URL')で GET リクエストができる.- レスポンスに対して
.textとすることで, レスポンスボディをテキスト形式で取得できる
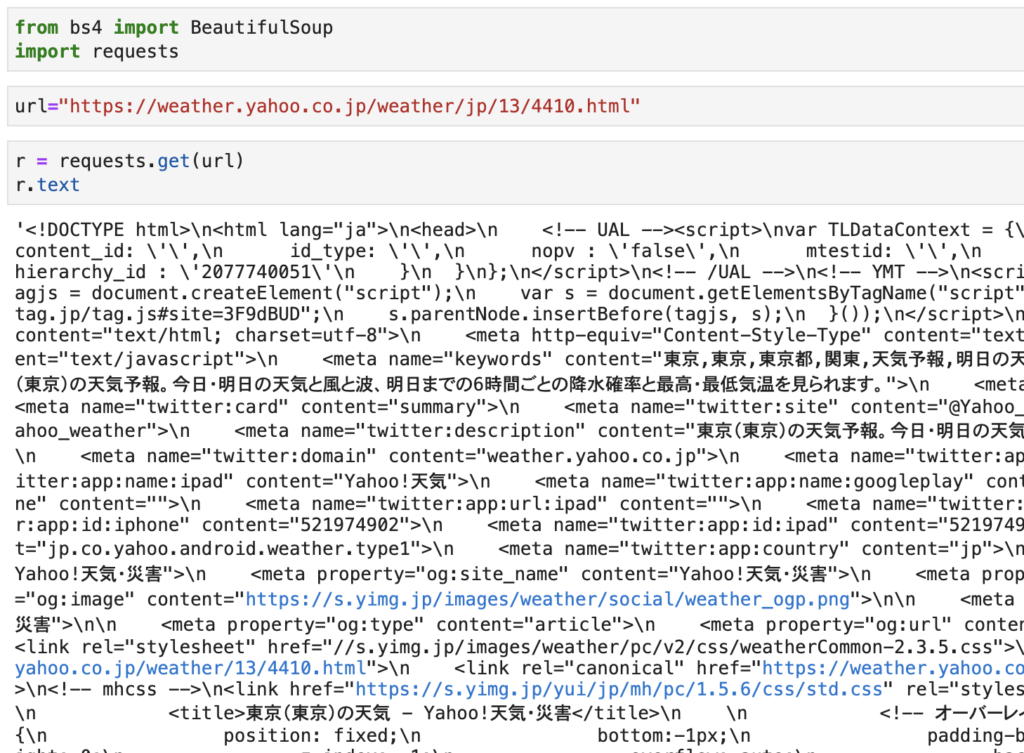
上記のとおり、r.text とすると、指定したURLのhtmlファイルの内容をテキスト形式で取得することができます。
ただし、これだと文字が羅列しているだけなので、次に説明するBeautifulSoupを使用してhtml形式に整形します。
BeautifulSoup(r.text,'html.parser')
- BeautifulSoup( テキスト , 'html.parser')とすることでテキストをhtmlの形式で整形します
- 今回テキスト部分には「 r.text 」が入っていますが、これは前述にあるとおり指定したURLのファイルの内容をテキスト形式で取得したものになります
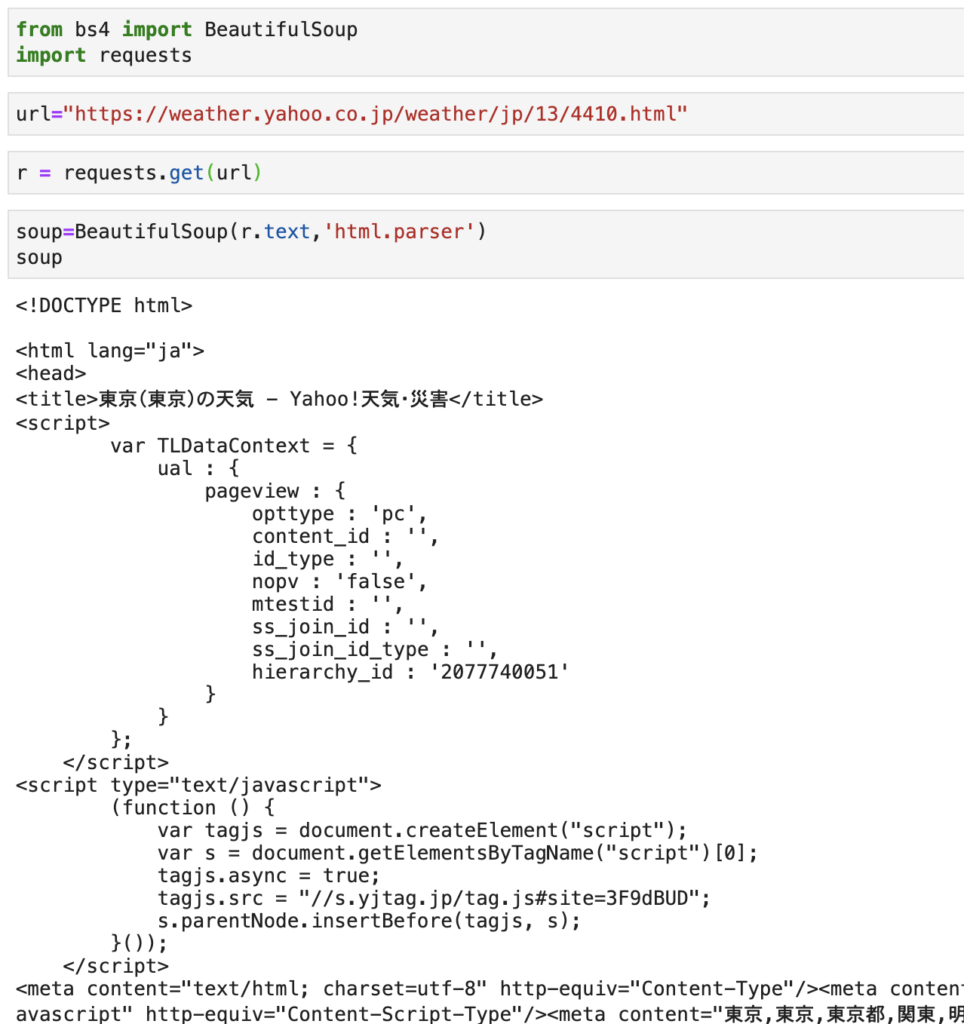
上記のとおり、html形式に整形することができました。
どこかのWebページから情報を取得する、いわゆるスクレイピングをするためには、この形式のデータを準備する必要があります。
- Webページのレスポンスボディを取得する
- レスポンスボディをテキスト形式に変換する
- テキストをhtml形式に整形する(いまココ!)
- html の class名を指名して、その内容を取り出す
- スライスを使用して特定のデータを取り出す
select(".high")[0].text[0:3]
select(".high")まで
- select は、クラス名を指定することで、そのクラス内のテキストを取得することができます
- 以下のように、selectはリストで返してくれます
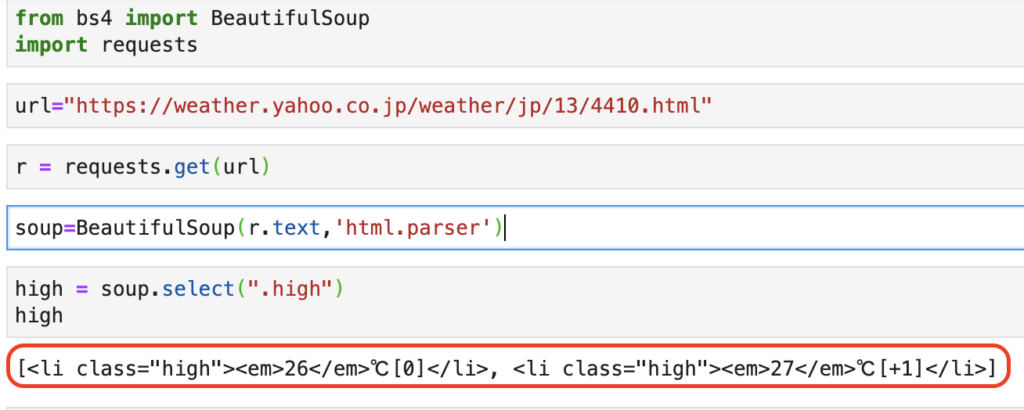
上記のとおり、リストの要素数が2つなので、class名が「high」の要素は2つあるようです。
実際に、指定しているURLのWebページを確認してみましょう。
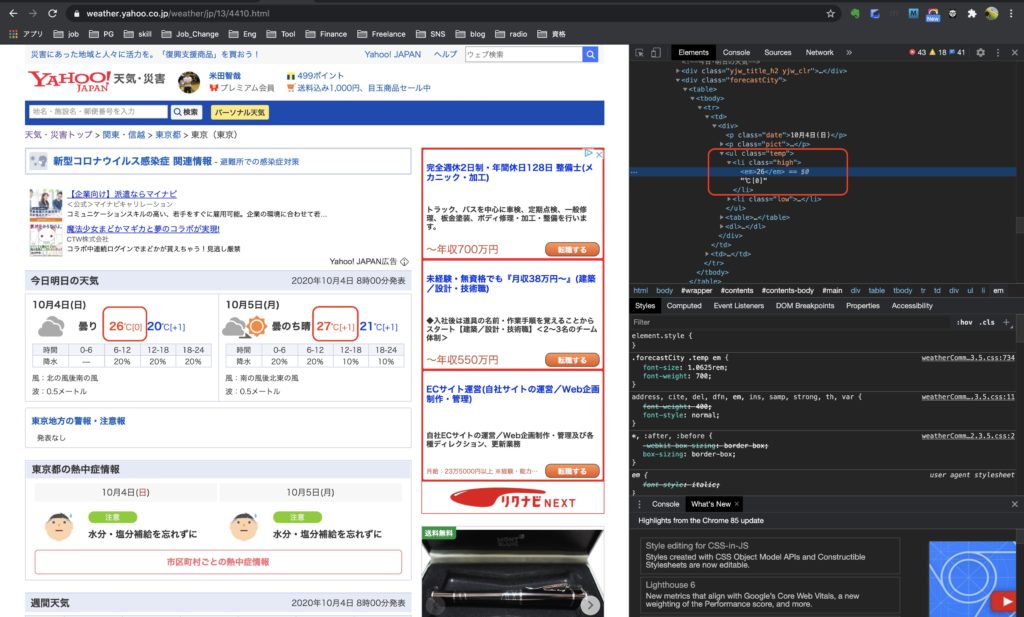
上記のとおり、Webページには当日の最高気温と翌日の最高気温が表示されています。
そのため、リストの要素数も2つ返ってきました。
ちなみに、ほしい情報をもつ要素のクラス名を調べるにはGoogle chromeの検証ツールが便利です。
[0]
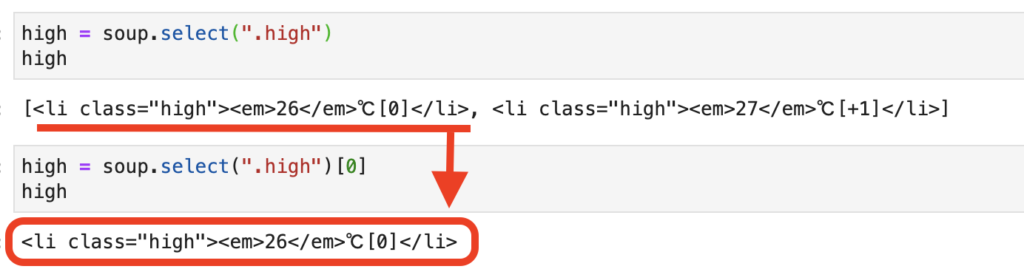
select(".high")は、リストが返ってきました。
今回使用したいのは、当日の最高気温のため、リスト内の最初の要素を使用します。
そのためリストの最初の要素をとってきています。
翌日の最高気温を使用したいときは、[1] に変更すればOKです。
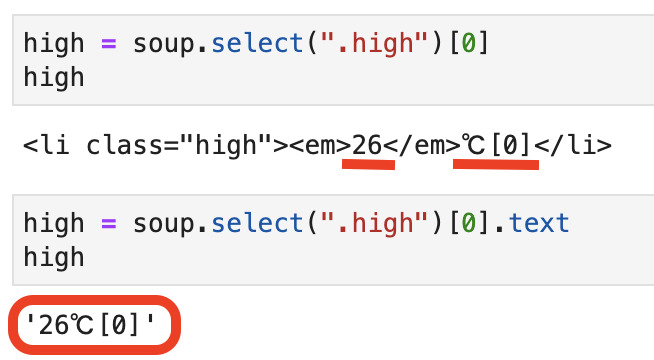
.text
.text をつけることで、タグを取り除いた文字列を取得することができます。
今回は、タグを取り除くと「26℃[0]」が取得されます。
この [0] は先ほどのリストから要素を取り出す時の [0] とは違うものなので注意してください。
この [0] はWebページの気温差を表す表示です。
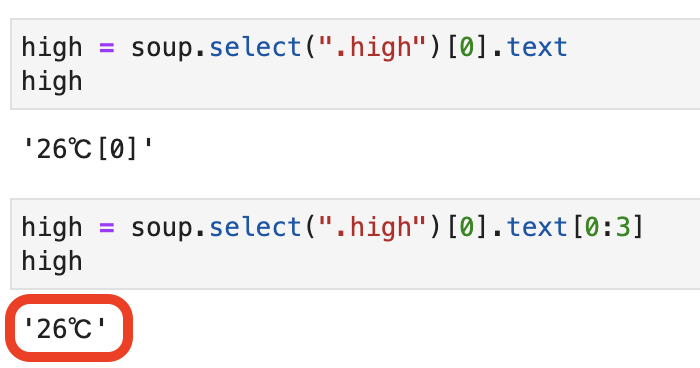
[0:3]
これはスライス操作です。
リスト、文字列、タプル、バイト列などの一部分をコピーして返してくれる仕組みを「スライス」と呼びます。
今回は、上記の '26℃[0]'の「26℃」の部分を使いたいので、インデックス番号0から2をコピーして使用します。
このデータを使用して、出力します。